SQL索引和事务
概念
索引(index)是帮助数据库高效获取数据的数据结构。
-
优点
- 提高数据查询的效率,降低数据库的IO成本。通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
-
缺点
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
数据结构
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。我们平常所说的索引,如果没有特别指明,都是指默认的B+Tree结构组织的索引。
B+ Tree多路平衡搜索树
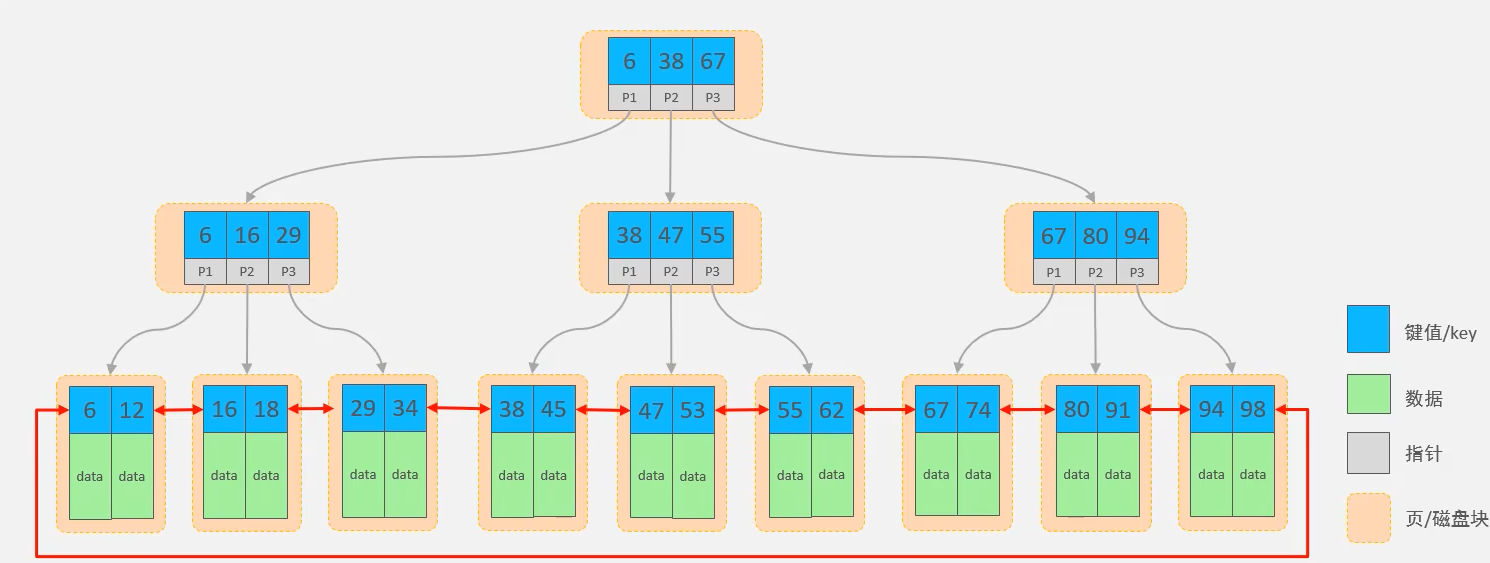
- 每一个节点,可以存储多个key(有个key,就有n个指针),
- 所有的数据都存储在叶子节点,章叶子节点仅用于素引数据。
- 叶子节点形度了一颗双向链表,便于数据的排序及区间范围查询。
语法
- 创建索引
create[unique]index 索引名 on 表名(字段名…);
1 | create index idx emp_name on tb_emp(name); |
- 查看索引
show index from 表名;
1 | show index from tb-emp |
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed |
|---|---|---|---|---|---|---|---|---|
| tb_emp | 0 | PRIMARY | 1 | id | A | 9 | ||
| tb_emp | 0 | username | 1 | username | A | 9 | ||
| tb_emp | 1 | idx_emp_name | 1 | name | A | 9 |
- 删除索引
drop index 索引名 on 表名;
注意事项
- 主键字段,在建表时,会自动创建主键索引。
- 添加唯一约束时,数据库实际上会添加唯一索引。
事务介绍
事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撒销操作请求,即这些操作要么同时成功,要么同时失败。
- 注意事项:默认MySQL的事务是自动提交的,也就是说,当执行一条DML语句,MySOL会立即隐式的提交事务。
事务控制操作
- 开启事务:start transaction; /begin;
- 提交事务:commit;
- 回滚事务:rollback;
事务的四大特性
原子性
事务是不可分割的最小单元,要么全部成功,要么全部失败
一致性
事务完成时,必须使所有的数据都保持一致状态
隔离性
数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
持久性
事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
事务成功提交的例子
假设我们有一个名为accounts的表,结构如下:
1 | CREATE TABLE accounts ( |
我们要从账户1转账给账户2,确保两条更新语句都成功,否则回滚。
1 | -- 开始事务 |
在这个事务中,两个更新操作必须都成功执行。如果一切顺利,事务会通过COMMIT提交,数据库中的更改会被永久保存。
事务失败后的回滚例子
假设在相同的转账操作中,账户1的扣款成功,但账户2因某种原因无法接收款项,我们需要回滚整个事务。
1 | -- 开始事务 |
在这个例子中,第二条UPDATE语句因为账户不存在导致失败,整个事务会被回滚,账户1的扣款操作也会被撤销,恢复到事务开始前的状态。
事务的关键步骤:
START TRANSACTION:开始一个事务。COMMIT:提交事务,如果所有操作都成功,数据库会保存这些更改。ROLLBACK:回滚事务,如果有任何操作失败,撤销事务中的所有更改。
在使用事务时,确保将多个相关的操作组合在一起,确保数据的一致性。如果任何操作失败,就可以通过ROLLBACK防止不完整的数据写入数据库。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.